云计算资源弹性伸缩是一种根据业务需求动态调整计算资源规模的技术。它可以根据系统的性能指标(如CPU使用率、内存占用率、磁盘IO、网卡读写率、请求响应时间等)或者预定义的规则(如时间周期、业务事件等),自动增加或减少计算资源的数量,以满足业务负载的变化。这种技术可以确保系统在高峰时期拥有足够的处理能力,而在低谷时期则能释放多余资源,从而实现资源的最大化利用。
简单说,就是监测资源指标,发现到达瓶颈的时候,进行资源增量,发现利用过剩的时候,进行资源缩减。
实现方案和原理
从云计算的容器化方面,有哪些办法呢?我们先来看看容器的一些配置。
容器的Request和Limit
resources:
limits: # 资源上限,不能超过该资源的阈值,否则会触发限制或者重启
cpu: "1"
memory: 8G
requests: # 资源下限,无论是否使用上,都会占据对应空间
cpu: 200m
memory: 500M
Request指标
Request表示容器在运行过程中所需的最小资源量,即容器启动时的资源保证。当Pod被调度到节点上时,Kubernetes会确保该节点上至少有足够的资源来满足Pod中所有容器的Request值。如果节点可用资源无法满足时,则Pod将不会被调度到该节点上,而会保持在Pending状态,直到找到满足条件的节点为止。因此,
合理设置Request值可以确保Pod的稳定性和可靠性。
Limit指标
Limit则表示容器在运行过程中可以使用的最大资源量,即容器可以消耗的资源上限。如果容器的实际资源使用量超过了Limit值,Kubernetes会采取相应的措施来限制容器的资源使用,例如限制CPU使用率、杀死进程等,以确保不会因资源不足而导致系统崩溃或性能下降。通过设置Limit值,
可以有效地防止单个容器或整个Pod占用过多的资源,从而影响整个集群的性能和稳定性。
也就是说 Requet 是下限,Limit 是上限。在实际使用中,需要 根据应用程序的特性和需求来合理设置Request和Limit值 ,以确保既能够满足应用程序的性能需求,又能够充分利用集群资源,避免资源浪费。
但是不可避免的,我们的容量评估没有那么标准。这时候,云计算如果能够根据策略有条件的进行自动伸缩,那会给我们解决很多麻烦。那 伸缩的策略又分为两种,垂直(VPA)和水平(HPA),下面我们详细来分析下。
VPA的算法实现
VPA全称Vertical Pod Autoscaler,即垂直Pod自动扩缩容。
它根据容器资源使用率自动设置CPU和内存的
requests/limits
,从而允许在节点上进行适当的容积调度,以便为每个Pod提供适当的资源。
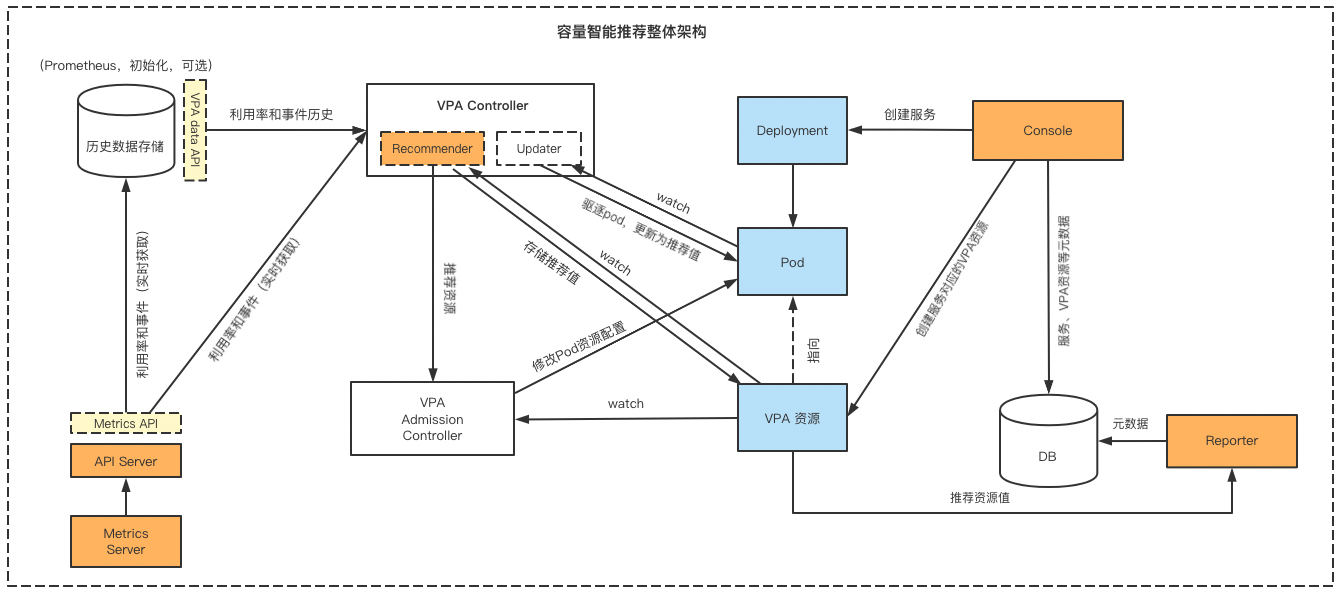
- Recommender 组件每隔 1 分钟采集 CPU 和内存的用量信息,
- 将采集到的数据放入Decaying ExPONEntial Histogram(衰减指数直方图)的 bucket 中,bucket 存放的是权重值,这样随着时间的推移就会生成一个分布图。衰减直方图参考下面算法分析。
- 算出指数直方图的 P95,P90,P50 对应 bucket 的起始值就是推荐值(设为 estimation95,estimation90,estimation50),但这其实不是最终的推荐值
- 为了保证推荐值的安全性,还会给这些数据乘以安全边际系数(safetyMarginFraction )和置信乘数(confidenceMultiplier)
- 最终算出来的值才是真正的推荐值,这三个值分别是 VPA 推荐值的 upperBound(推荐上线)、target(推荐目标值)、lowerBound(推荐下限)
公式如下:
-
推荐 Request最大值:
\(upperBound = estimation95 * (1 + 1/history-length-in-days)\) -
推荐 Request 值:
\(target = estimation90*(1+safetyMarginFraction)\) -
推荐 Request 最小值:
\(lowerBound = estimation50 * (1 + 0.001/history-length-in-days)^{-2}\)
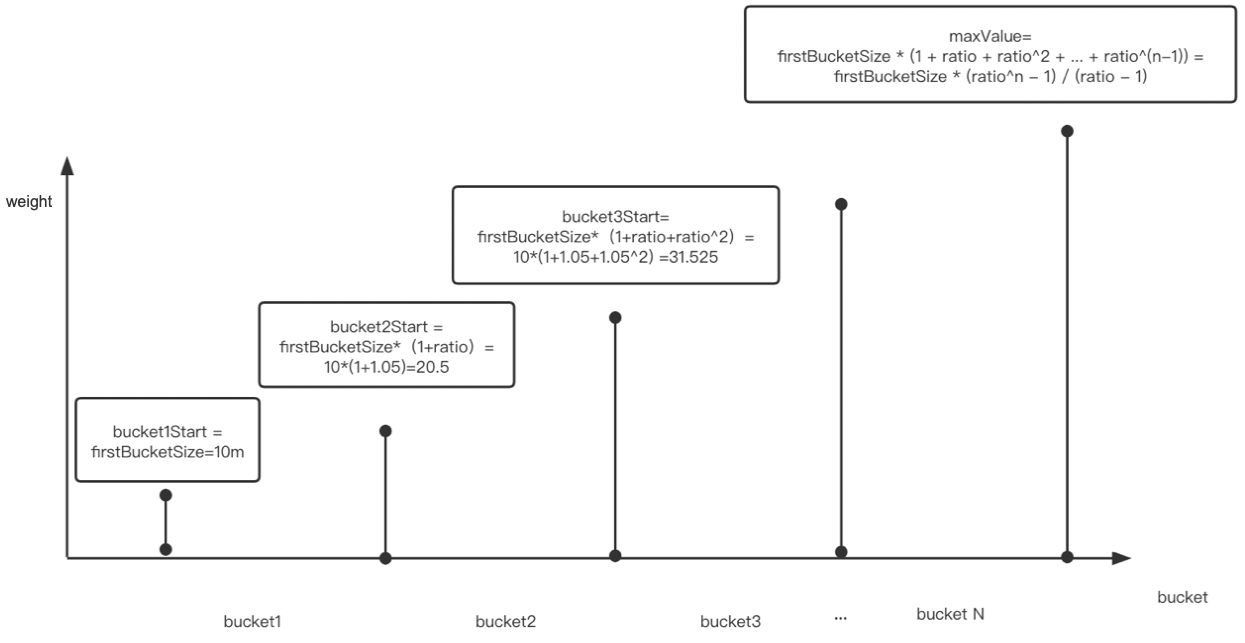
衰减指数直方图简介
DecayingExponentialHistogram
衰减的意思是直方图中的样本的权重值会随着时间的增长,权重会逐步降低,也就意味着最新的样本数据对推荐值的影响更大。
。指数直方图的意思是直方图的步长是指数增长的,假设第一个 bucket 是 firstBucketSize 大小,那么索引为 n 的 bucket 大小就是 firstBucketSize * ratio^n,ratio 是固定的系数。第 n 个 bucket 的起始值就是:
\(firstBucketSize * (1 + ratio + ratio^2 + ... + ratio^{(n-1)}) = firstBucketSize * (ratio^n - 1) / (ratio - 1)\)
如下(CPU样本指数直方图):
HPA的算法实现
HPA全称Horizontal Pod Autoscaler,即水平Pod自动扩缩容。
简单说就是 增加实例数量,调整replicas副本数,来满足资源扩容的过程 。
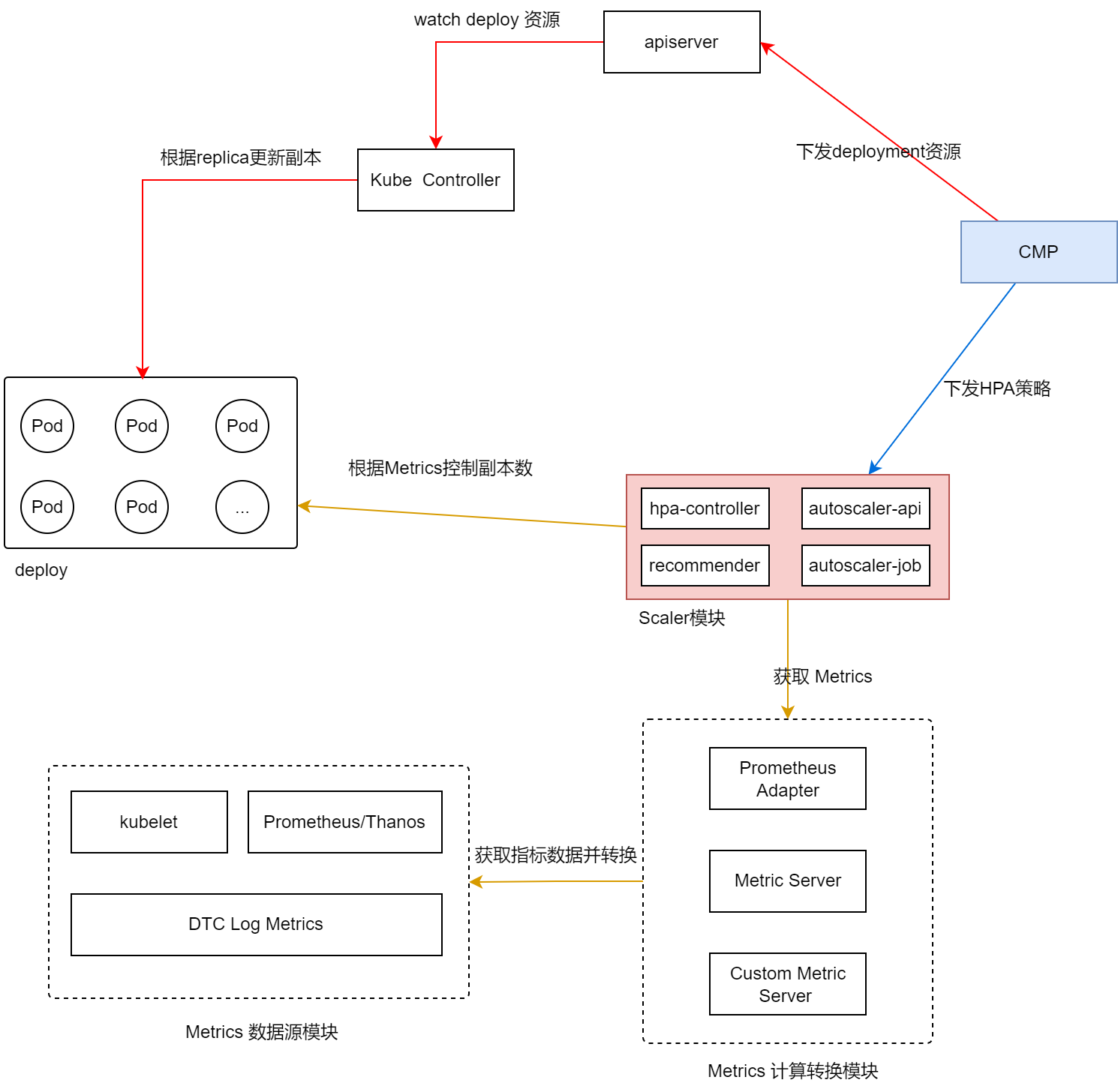
- Recommender 组件每隔 1 分钟采集 CPU 和内存的用量信息,
- CMP配置HPA策略和扩容任务
- Metric Server 采集kube资源的各种指标
- 如果达到策略阈值,则进行扩容
- 下面这个例子中,我们使用了 CPU 利用率 的度量指标,并且设置目标 CPU 利用率为 60%,大于该值启动扩容。
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 1 # 最少副本数1
maxReplicas: 10 # 最多副本数10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
我们要求的是CUP不超过60%,所以反向计算合理副本的办法如下:
计算逻辑:当前期望副本数 = ceil(当前副本数 * (当前指标/期望指标数))
举例:
当前指标:CPU利用率 70%
期望指标:CPU利用率60%
当前副本数:10
期望副本数:ceil(10*(70/60))=12
最终扩容数量为2
架构带来的启发
如果有看过我的MySQL系列和Redis系列,一定对其中的分库分表、分片(Sharding)印象深刻,其实同一个道理。
就是
当资源不够的时候进行增强和拆分负载的做法,我们称之为分治思维。
弹性伸缩的模式是让这一个过程变得更加自动化了,后续我们继续分享下存储层的动态伸缩,那我们的整个系统是不是就变得更加弹性了?
总结
弹性伸缩技术是云计算领域的一项重要技术,它通过动态调整计算资源规模来满足业务负载的变化需求。在实际应用中,我们需要根据具体的业务场景和负载类型选择合适的监控指标和伸缩策略,并充分利用自动化脚本和工具来提高操作的效率和准确性。同时,我们还需要建立完善的监控与告警机制来确保系统的稳定性和可靠性。随着云计算技术的不断发展和应用场景的不断拓展,弹性伸缩技术将在未来发挥更加重要的作用。
★ 总结部分通过AI对全文内容进行理解并总结











