CPU要执行指令需要先识别指令,弄清楚要执行的指令是什么类型、需要几个周期、操作数在哪里、目的地在哪里等信息,才能在后续的指令执行过程中打开对应的数据通路。“识别指令”的过程叫译码,完成指令识别功能的机构,叫译码器。
因为6502 CPU有一个两级流水线,所以有两个译码器,分别叫前置译码器(Pre-Decoder)和后置译码器。通常说的6502译码器实际是指后置译码器。这两个译码器在电路图中位置如下图:
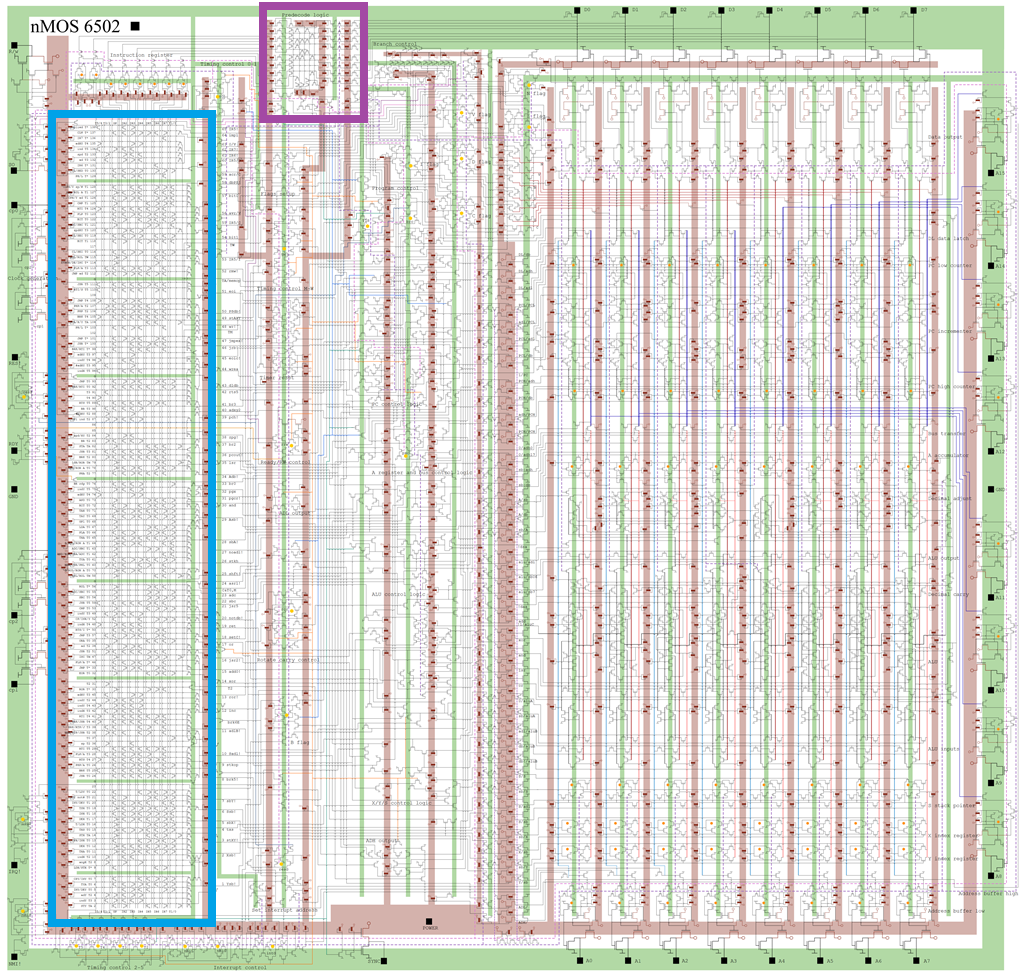

图中,紫色表示前置译码器,蓝色表示后置译码器。我没有在6502 Schematics.pdf文件中找到前置译码器,可能是作者没有整理出来。
两个译码器之间的协作关系可以从Hanson's Block Diagram中看出来:
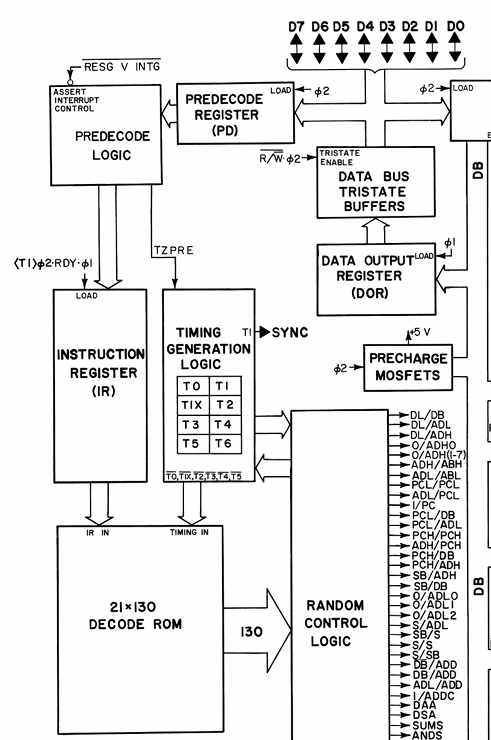
可以看到,前置译码器在指令寄存器(IR)之前,而后置译码器在IR之后。后置译码器负责对正在执行的指令进行译码,而前置译码器则对将要执行的指令进行简单译码。
前置译码器与后置译码器都遵循同样的译码原理,观察它们的电路,都长得如下图:
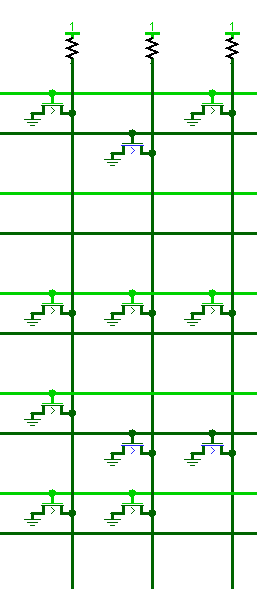
图中,横着的线为输入线,竖着的线为输出线。不难看出,译码器的输出其实是一个多输入或非逻辑。由于或非逻辑只能识别逻辑1,所以为了能识别逻辑0,通常还会把原数据取反后加入到输入中。上图中亮绿色的线与它下方的暗绿色线互为反信号。
为了说明译码器原理,让我们看一个简化版本的译码器。下图是一个4入2出的译码器,我们以它为模型进行说明。
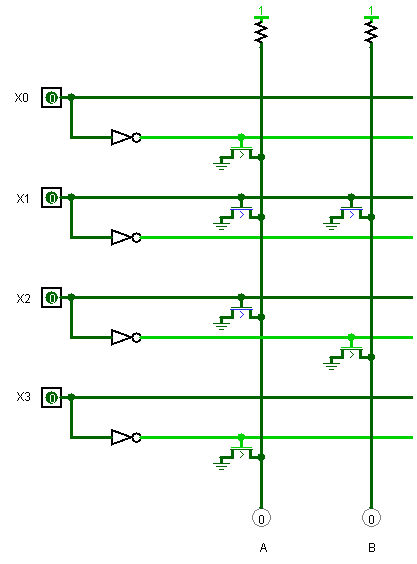
前面说到,输出是或非逻辑。所以\(A=\overline{\overline{X_0}+X_1+X_2+\overline{X_3}}\),化简可得\(A=X_0\overline{X_1}\overline{X_2}X_3\),可知A可以识别的输入模式为1001,即可以识别0x9。同理可得\(B=\overline{X_1}X_2\),即B可以识别的输入模式为x10x。
前置译码器负责对将要执行的指令进行简单译码,因此译码输入是总线数据。总线数据被暂存到前置译码寄存器(PD)中,避免总线数据变化影响译码结果。每个时钟周期,总线数据都会重新加载到PD中。下图是前置译码器整理过后的电路图:
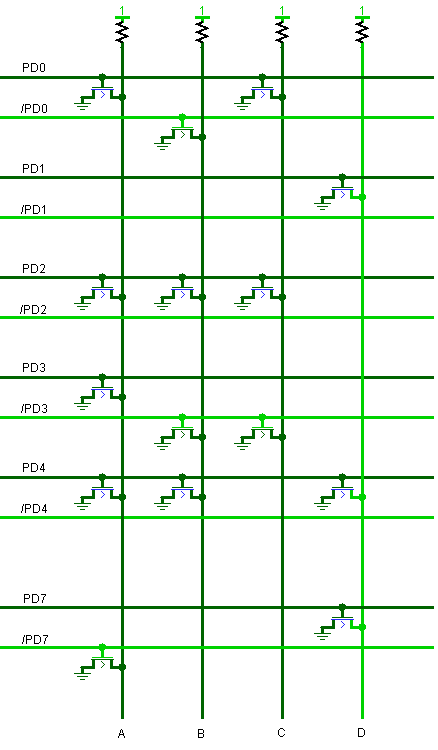
应用前面介绍的分析法,可以得到前置译码器输出如下:
| 输出 | 匹配模式 | 说明 |
|---|---|---|
| A | 1xx000x0 | LDX #, LDY #, CPX #, CPY # |
| B | xxx010x1 | 立即数算术指令 |
| C | xxxx10x0 | 隐式(Implied)寻址指令 |
| D | 0xx0xx0x | 栈操作指令、流程控制指令及算术指令 |
译码后,A、B、C、D又按照\(\overline{A+B+C\overline{D}}\)的方式组合出一个新的信号,这个新信号表示指令不属于2周期指令。
后置译码器负责对正在执行的指令进行译码,因此输入数据是指令寄存器中的内容。此外,它的输入还包含了当前的时钟周期,因此可译出当前指令是什么类型及是第几个周期。6502 Schematics.pdf已经标注出了译码结果,本文不再赘述。GitHub上有一个项目-emu russia-对6502做了非常彻底的研究,其中当然也包括对译码器的研究。感兴趣的读者可以参考他们的成果,里面有译码器输出的详细说明。
6502的译码器占据了芯片很大一块地方,是指令识别的核心,粗看之下可能觉得译码器非常神奇或者非常复杂,希望本文的介绍能让你祛魅。回头再想想,其实我们可以把译码器看做成一个只读内存,只不过存储的是一个130位的超大数。正是这个原因,有时候6502的译码器又叫解码器只读内存(Decoder ROM)。
为了将输入模式对应的指令标识出来,我做了一个小工具:
如果无法看到演示界面,可以点击此处体验。
【说明】:
- 输入“xxxx10x0”点击“确定”即可查看所有匹配的指令。
- 工具还支持表达式,例如输入“1xx000x0 || xxx010x1 || (xxxx10x0 && ~0xx0xx0x)”再点击“确定”即可查看所有满足表达式的指令。
参考
- 6502 Schematic.pdf
- 6502 Circuit Diagram
- EMU rassia - 6502 decoder
- 6502 decoder tool











