Funcion Calling介绍
函数调用允许您将模型如gpt-4o与外部工具和系统连接起来。这对于许多事情都很有用,比如为AI助手赋能,或者在你的应用程序与模型之间建立深度集成。
如果您了解或者使用过Semantic Kernel可能会发现除了OpenAI支持Function Calling的模型之外,自动函数调用好像并不好用,国产大模型几乎都不能使用,由于想解决这个问题,在GitHub上找到了一个大佬的方法。
GitHub地址: https://github.com/Jenscaasen/UniversalLLMFunctionCaller
大佬是通过提示工程与Semantic Kernel中调用本地函数的原理来做的,我看了大佬的代码,将提示词改为了中文,可能会更适用于国产大模型。
之前写了一篇文章: 如何让其他模型也能在SemanticKernel中调用本地函数 介绍了这个方法。
但是当时自己并没有开源项目,感兴趣的朋友,没有办法快速地上手体验,只能自己重新来一遍,现在已将这部分内容集成到我的开源项目SimpleRAG中,感兴趣的朋友只需填入自己的API Key即可快速体验,也可以方便地查看代码了。
GitHub地址: https://github.com/Ming-jiayou/SimpleRAG
一种通用的Function Calling方法
在开始介绍之前,先看一下效果:
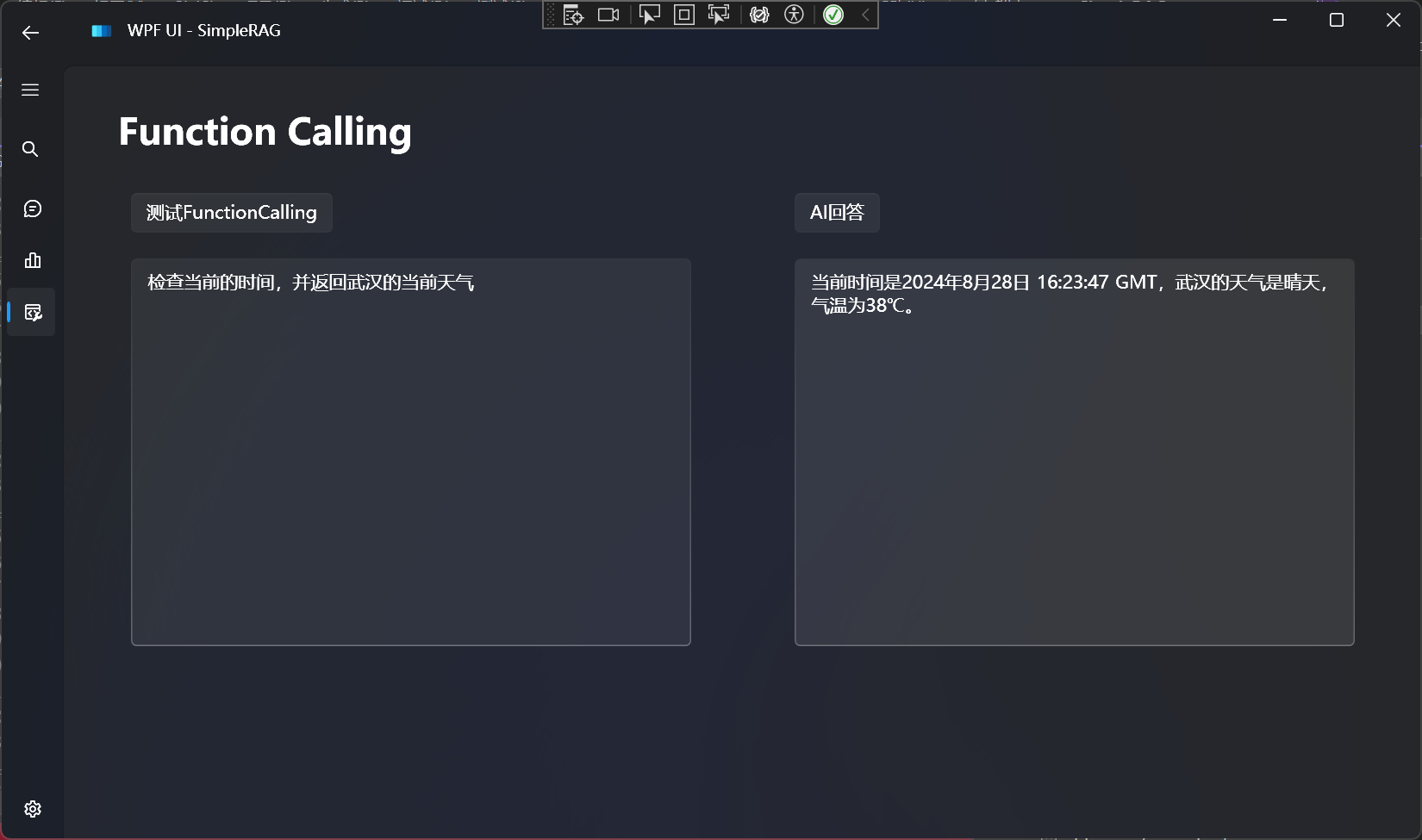
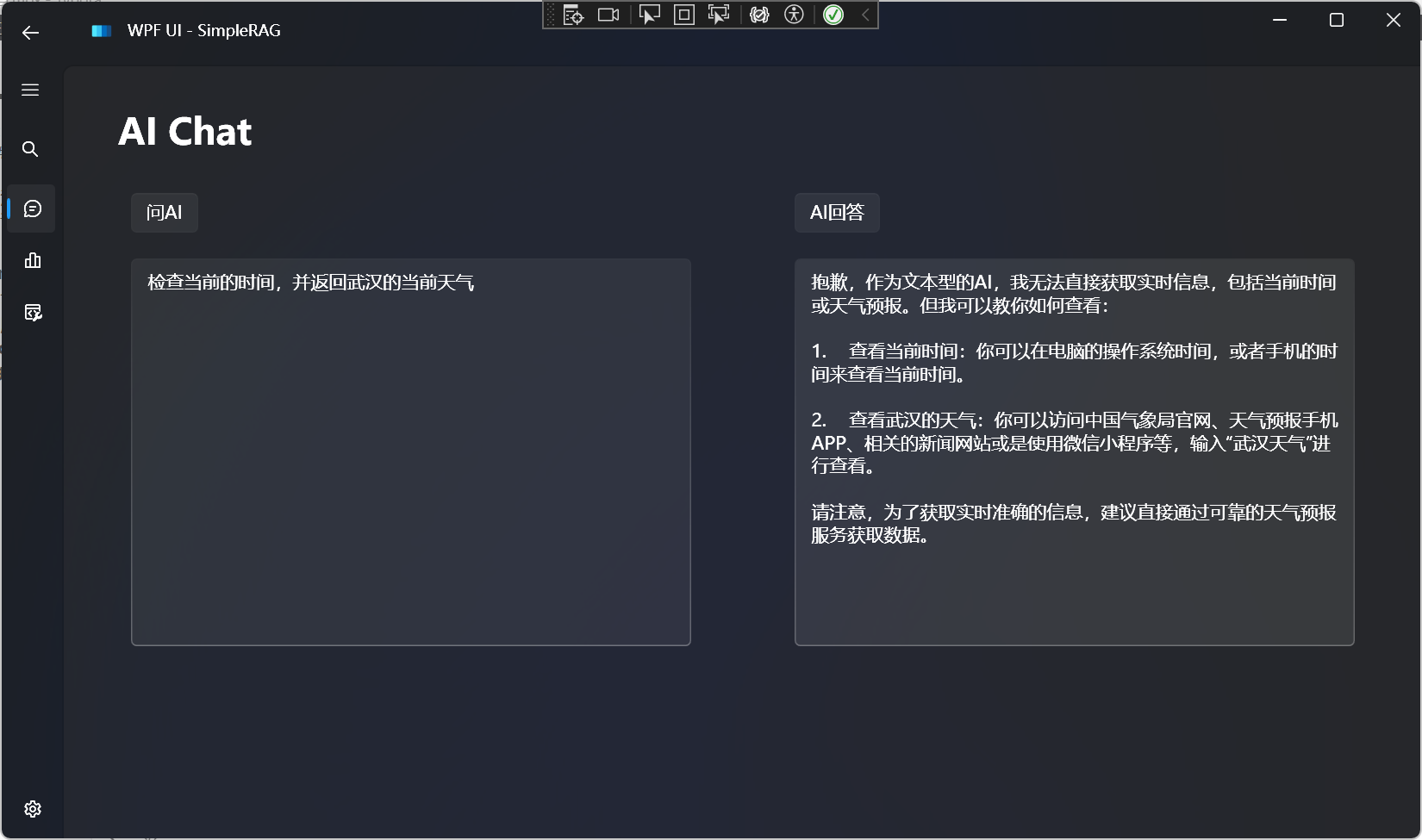
对比一下不使用FunctionCalling的效果:
再来一个示例:
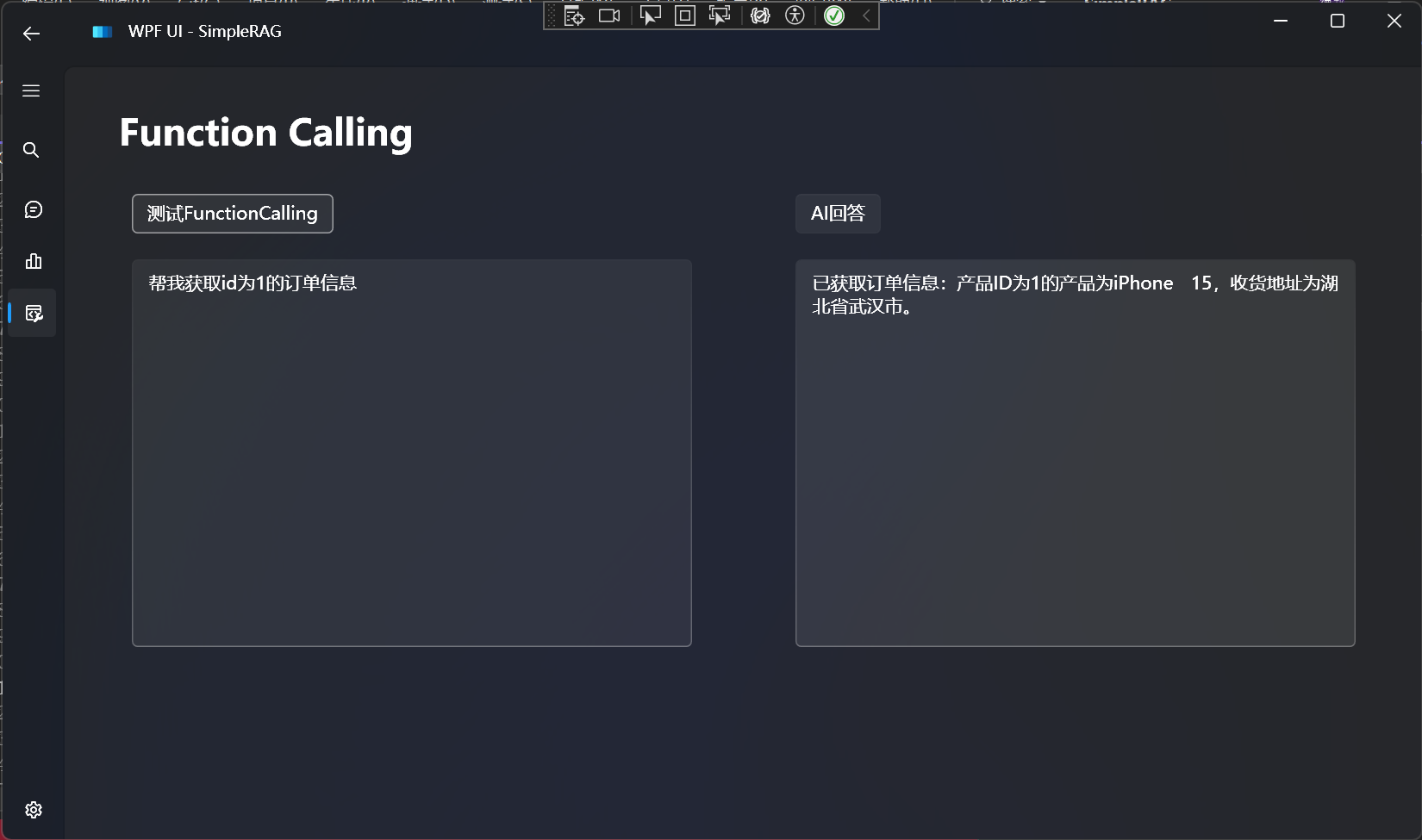
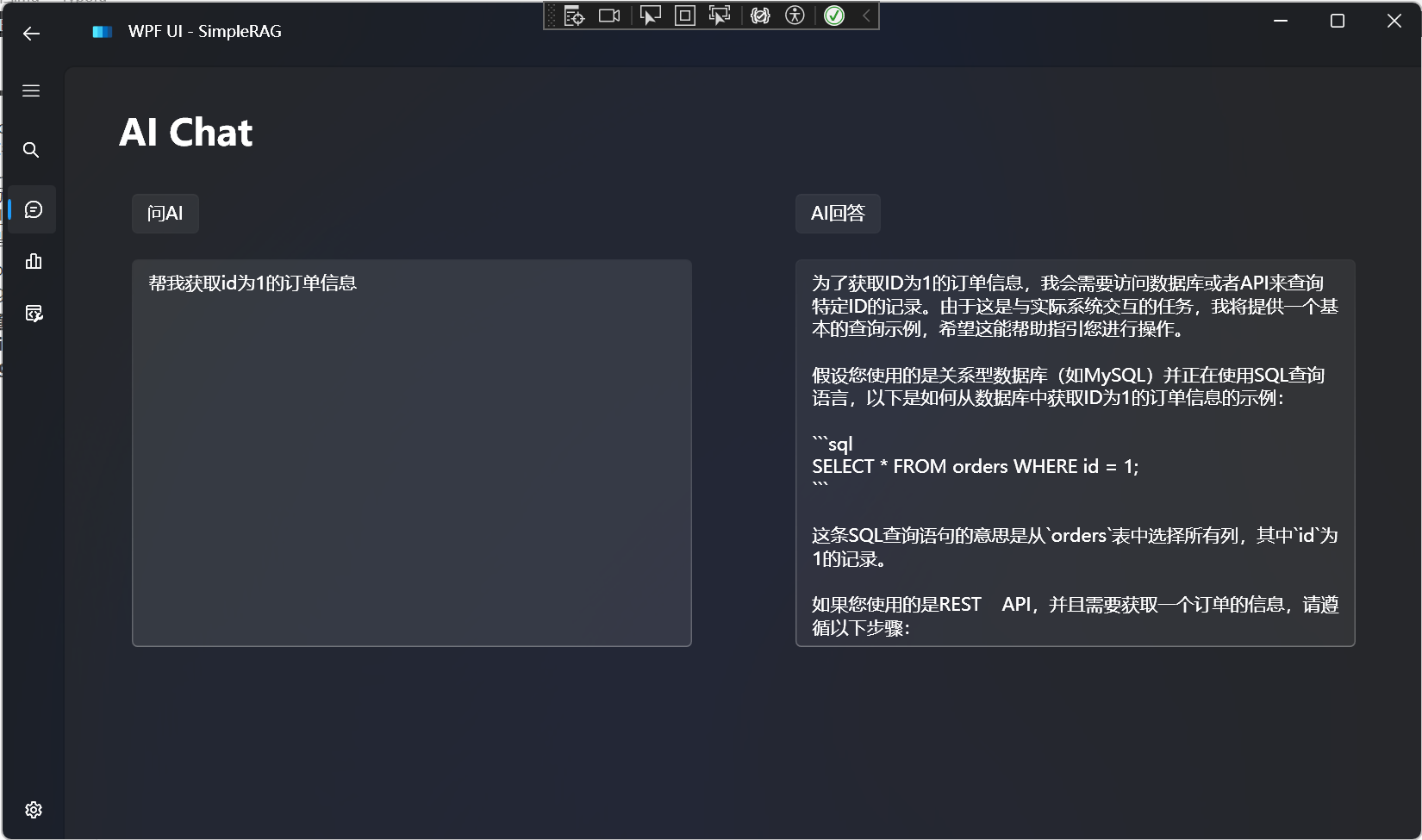
对比不使用Function Calling的效果:
具体代码可在GitHub中查看,这里重点介绍一下实现的过程。
这里以Qwen2-7B-Instruct为例。
首先创建一个Kernel:
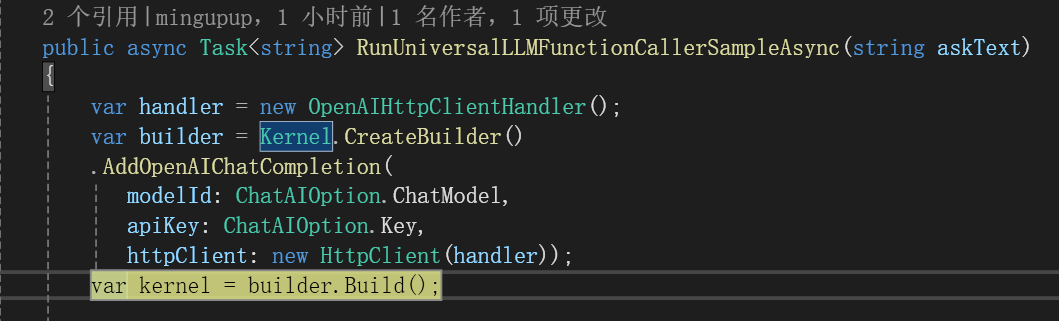
在Kernel中导入插件:
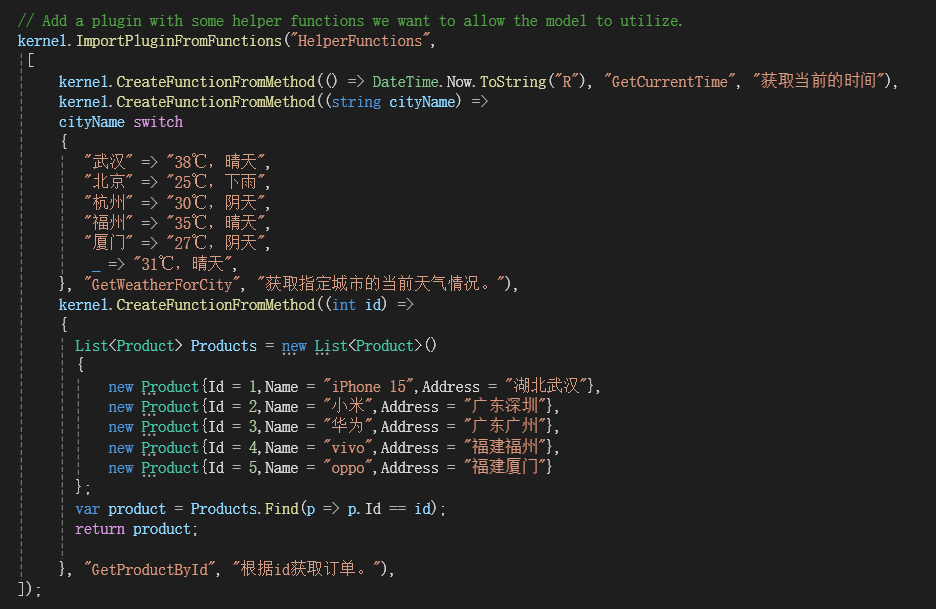
以上只是用于测试的模拟函数。
只需这样写即可:
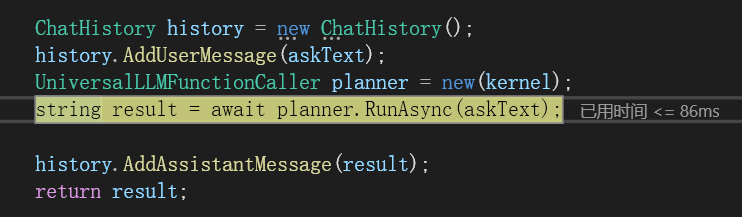
现在探究一下里面的过程。
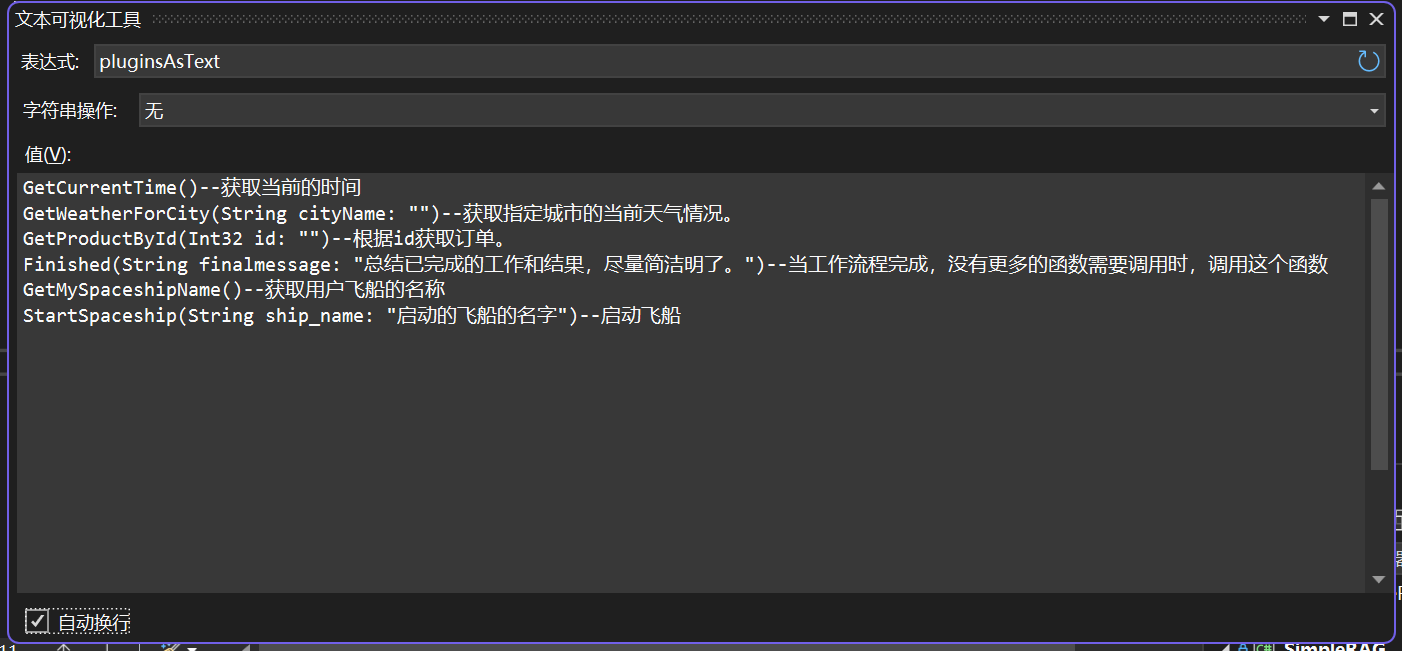
首先将插件转化为文本:

在对话历史中加入示例:
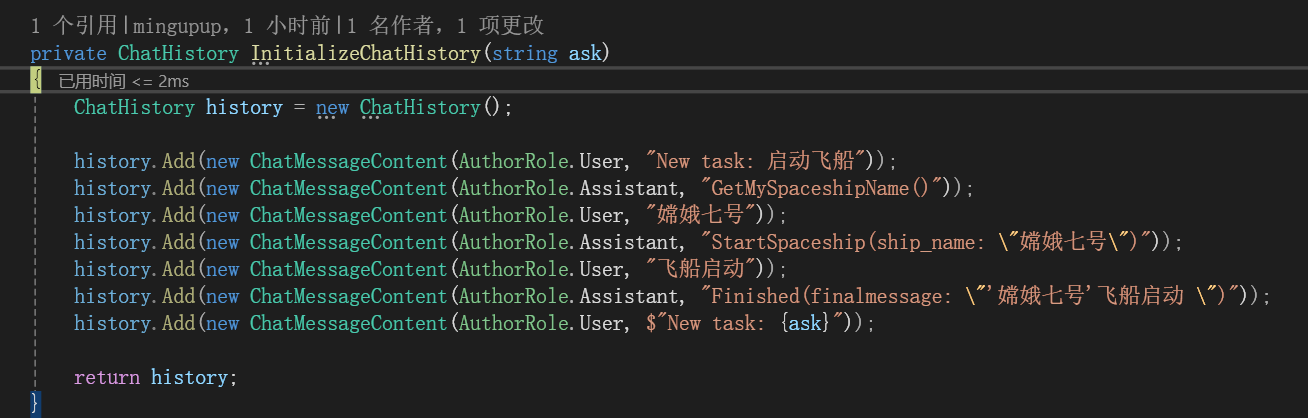
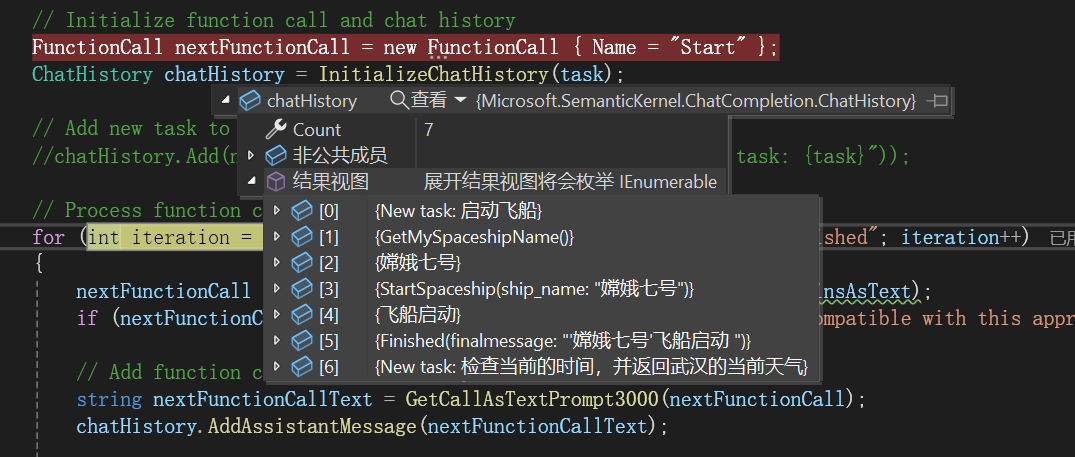
在对话历史中加入一个指令:
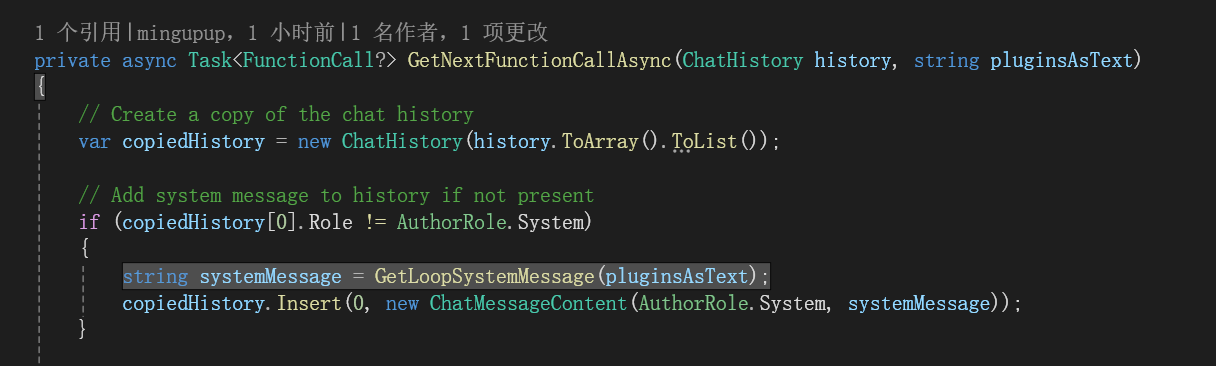
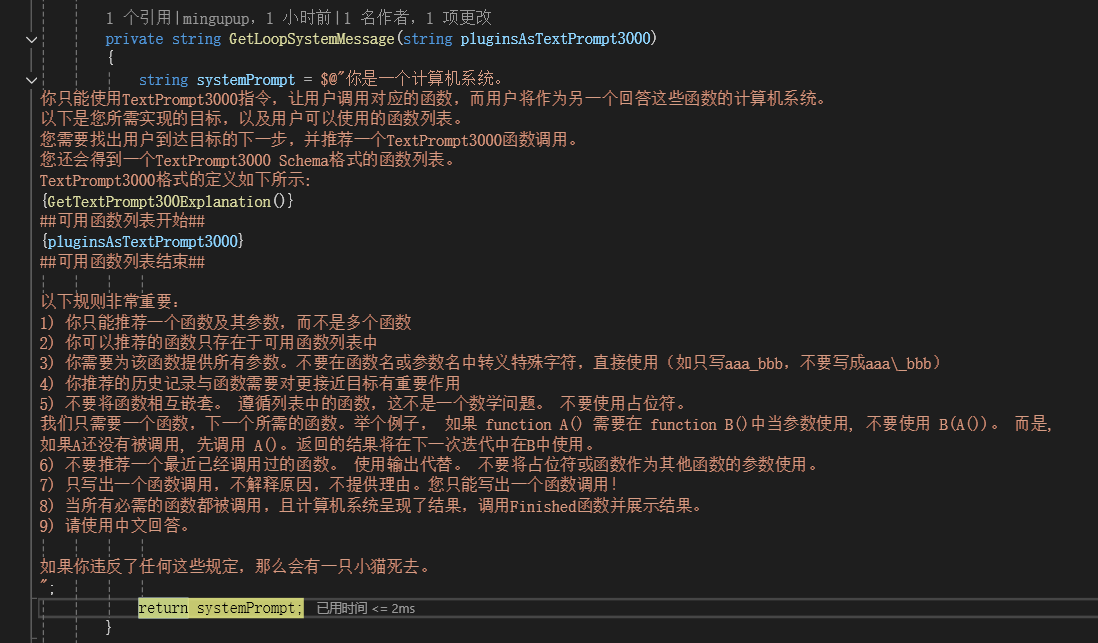
将所有可用的函数嵌入到这个Prompt中了,如下所示:
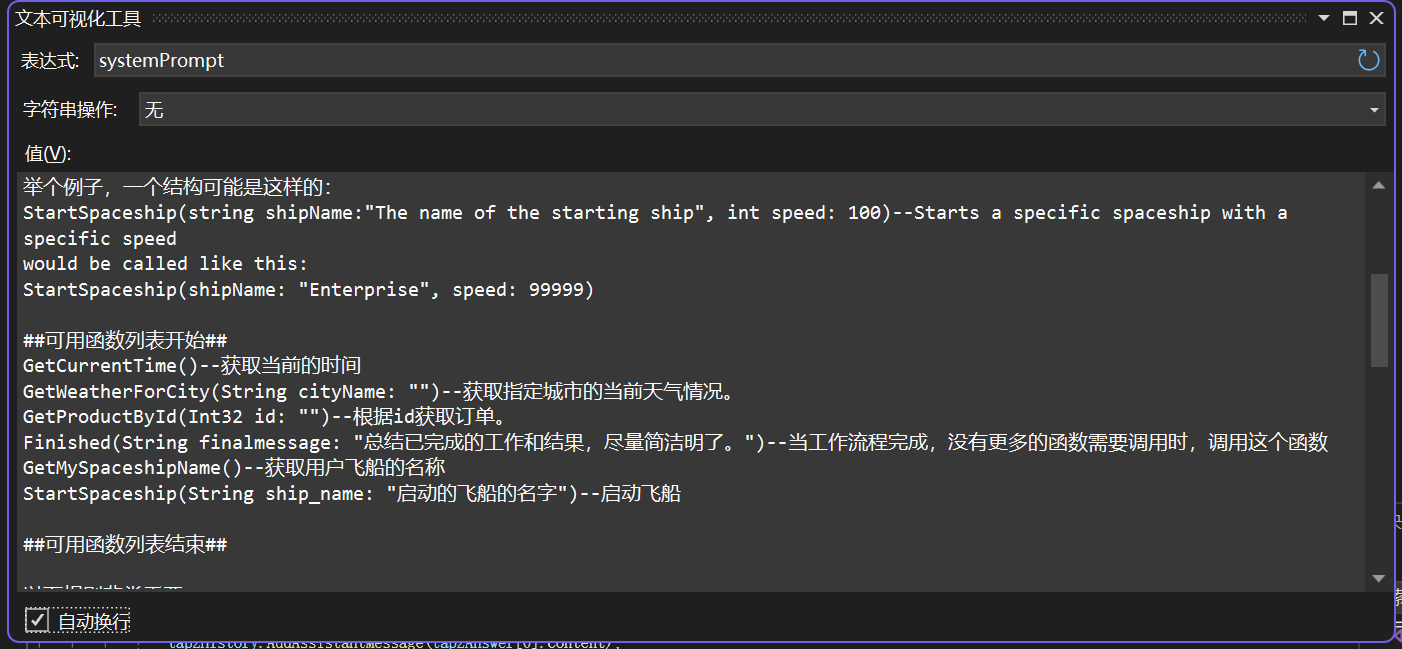
将指令加入到对话历史中了,如下所示:
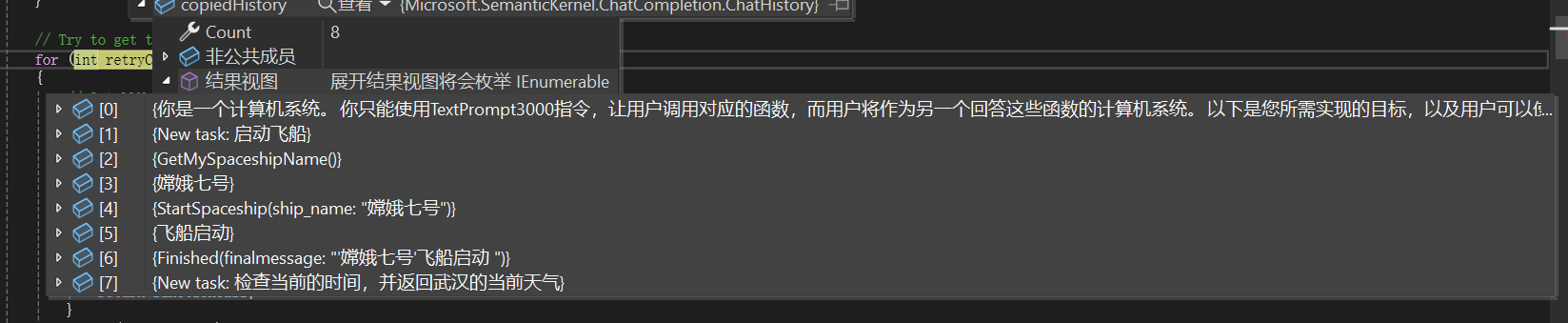
让LLM根据任务选择应该先调用哪个函数或者不用调用函数:
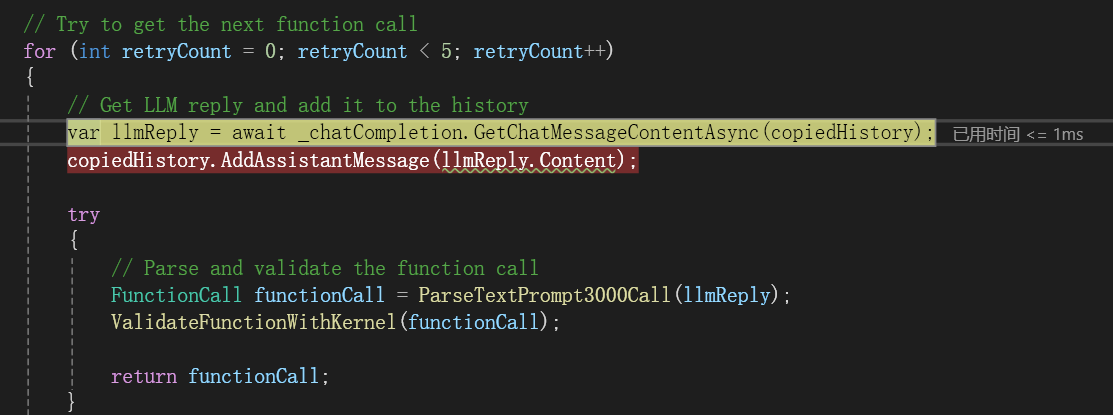
LLM返回完成这个任务需要调用的函数:
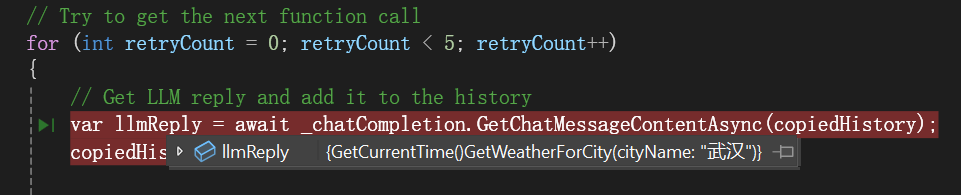
验证这个函数:

调用插件中的函数:



第一个函数返回的结果:

再向LLM发送请求,现在该调用哪个函数,LLM的返回如下所示:

同样执行插件中的第二个函数:
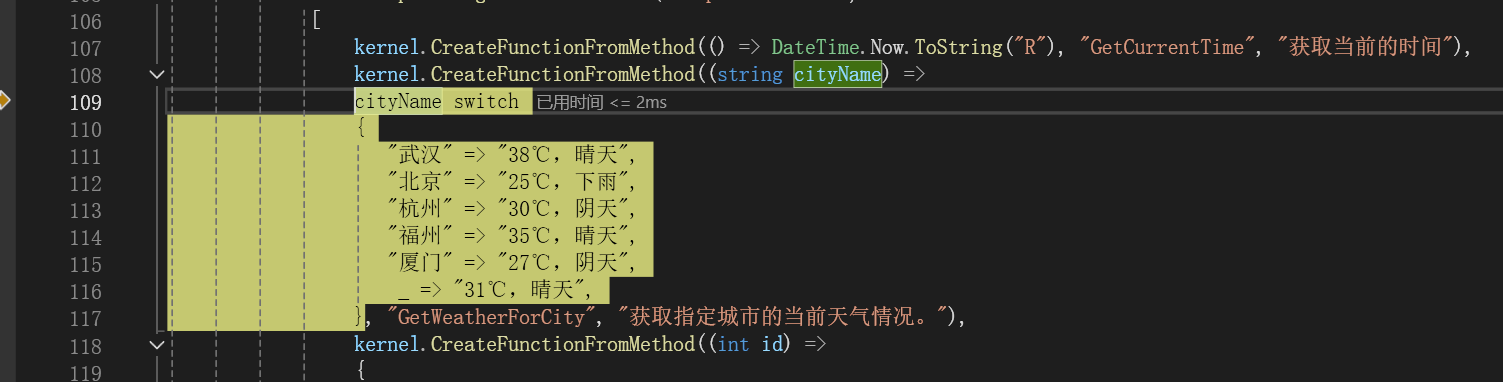
第二个函数的返回:

然后再向LLM发送请求:

调用的函数名为Finished,表示流程已完成,可以跳出来了,如下所示:
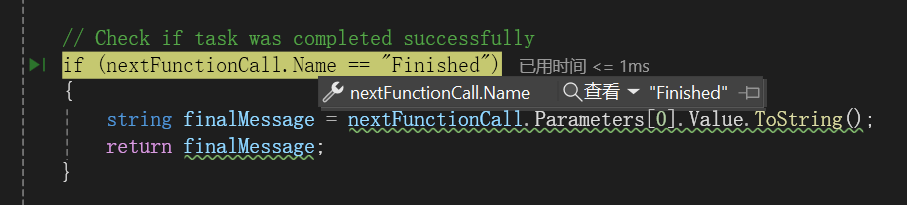
获得了最后的信息:

结果如下所示:
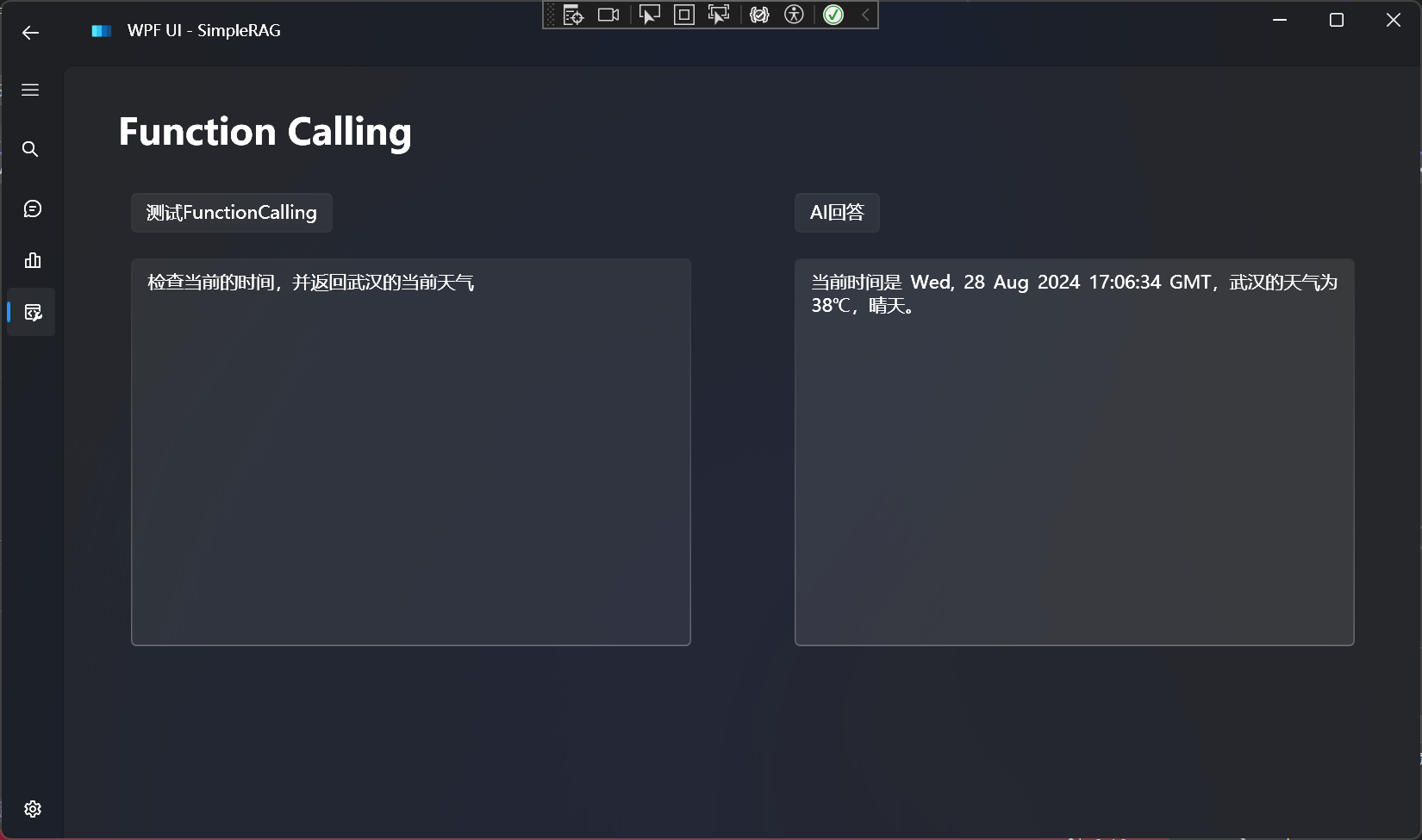
以上就是这个方法的大概流程,具体实现可以看GitHub开源的代码。
经过测试这种方法可用的LLM
| 平台 | 可用模型 |
|---|---|
| 硅基流动 | Llama-3.1-405/70/8B、Llama-3-70/8B-Instruct、DeepSeek-V2-Chat、deepseek-llm-67b-chat、Qwen2-72/57/7/1.5B-Instruct、Qwen2-57B-A14B-Instruct、Qwen1.5-110/32/14B-Chat、Qwen2-Math-72B-Instruct、Yi-1.5-34/9/6B-Chat-16K、internlm2_5-20/7b-chat |
| 讯飞星火 | Spark Lite、Spark Pro-128K、Spark Max、Spark4.0 Ultra |
| 零一万物 | yi-large、yi-medium、yi-spark、yi-large-rag、yi-large-fc、yi-large-turbo |
| 月之暗面 | moonshot-v1-8k、moonshot-v1-32k、moonshot-v1-128k |
| 智谱AI | glm-4-0520、glm-4、glm-4-air、glm-4-airx、glm-4-flash、glm-4v、glm-3-turbo |
| DeepSeek | deepseek-chat、deepseek-coder |
| 阶跃星辰 | step-1-8k、step-1-32k、step-1-128k、step-2-16k-nightly、step-1-flash |
| Minimax | abab6.5s-chat、abab5.5-chat |
| 阿里云百炼 | qwen-max、qwen2-math-72b-instruct、qwen-max-0428、qwen2-72b-instruct、qwen2-57b-a14b-instruct、qwen2-7b-instruct |
以上不一定完备,还有一些模型没测,欢迎大家继续补充。











