1. LLM 推理 - TensorRT-LLM 与 Triton Inference Server
随着LLM越来越热门,LLM的推理服务也得到越来越多的关注与探索。在推理框架方面,tensorrt-llm是非常主流的开源框架,在Nvidia GPU上提供了多种优化,加速大语言模型的推理。但是,tensorrt-llm仅是一个推理框架,可以帮助我们完成模型的加载与推理。若是要应用在生产上,仍需要与推理服务例如Triton Inference Server进行配合。
本文会介绍TensorRT-LLM与Triton的基本原理,并展示使用这两个组件部署LLM推理服务的流程。同时也会介绍其中使用到的推理优化技术。
2. 基础环境
硬件:1 x A10 GPU(24GB显存)
操作系统:Ubuntu 22.04
3. TensorRT-LLM
TensorRT-LLM是一个易于使用的Python API,用于定义大型语言模型(LLM),并构建包含最先进优化的TensorRT引擎,以在NVIDIA GPU上高效执行推理。TensorRT-LLM包含用于创建执行这些TensorRT引擎的Python和C++运行时的组件。它还包括与NVIDIA Triton推理服务器集成的后端。使用TensorRT-LLM构建的模型可以在从单个GPU到多个节点(使用张量并行或/和管道并行)的多个GPU的广泛配置上执行。
为了最大化性能并减小内存占用,TensorRT-LLM允许使用不同的量化模式执行模型(参考支持矩阵)。TensorRT-LLM支持INT4或INT8权重(和FP16激活;又称INT4/INT8仅权重),以及SmoothQuant技术的完整实现。
下面我们先使用TensorRT-LLM来进行模型的推理,然后介绍TensorRT-LLM在提升推理性能上做的部分优化。
3.1. 设置TensorRT-LLM环境
下面我们参考TensorRT-LLM的官网[1]进行设置。
|
# 安装docker sudo apt-get install docker # 部署nvidia ubuntu容器 docker run --runtime=nvidia --gpus all -v /home/ubuntu/data:/data -p 8000:8000 --entrypoint /bin/bash -itd nvidia/cuda:12.4.0-devel-ubuntu22.04 # 进入容器后安装TensorRT-LLM # 安装0.9.0版本,还需要使用低版本的numpy # 虽然目前最新版是0.10.0,但是必须安装0.9.0版本 # 因为后续使用triton镜像时,里面的tensorrt_llm最新版本只到0.9.0 pip3 install tensorrt_llm==0.9.0 -U --extra-index-url https://pypi.nvidia.com pip3 install numpy==1.26.0 # 检查是否安装成功 > python3 -c "import tensorrt_llm" [TensorRT-LLM] TensorRT-LLM version: 0.9.0 |
3.2. 模型推理
在设置好TensorRT-LLM的环境后,下面对llama2模型进行推理测试。
(这里为什么没有用最新的Llama3是因为在尝试做部署与推理Llama3-8B-Chinese-Chat模型的过程中遇到了一个暂时未解决的问题,具体报错为:RuntimeError: 【TensorRT-LLM】【ERROR】 Assertion failed: mpiSize == tp * pp (/home/jenkins/agent/workspace/LLM/release-0.10/L0_PostMerge/tensorrt_llm/cpp/tensorrt_llm/runtime/worldConfig.cpp:99))。)
下面是具体过程:
|
# 安装hugging face 环境 pip install -U huggingface_hub # 进入与本机磁盘mapping的data目录 cd data # 下载模型 huggingface-cli login --token **** huggingface-cli download --resume-download meta-llama/Llama-2-7b-chat-hf --local-dir llama-2-7b-ckpt # 下载TensorRT-LLM源码 git clone -b v0.9.0 https://GitHub.com/NVIDIA/TensorRT-LLM.git cd TensorRT-LLM git lfs install # 在加载模型前,需要先将模型格式转为TensorRT-LLM的checkpoint格式 cd examples/llama/ python3 convert_checkpoint.py --model_dir /data/llama-2-7b-ckpt --output_dir llama-2-7b-ckpt-f16 --dtype float16 # 然后编译模型 trtllm-build --checkpoint_dir ./llama-2-7b-ckpt-f16 \ --remove_input_padding enable \ --gpt_attention_plugin float16 \ --context_fmha enable \ --gemm_plugin float16 \ --output_dir ./trt_engines/llama2-f16-inflight-0.9/ \ --paged_kv_cache enable \ --max_batch_size 64 # 而后即可进行推理测试 python3 ../run.py --engine_dir ./trt_engines/llama2-f16 --max_output_len 100 --tokenizer_dir llama-2-7b-ckpt --input_text "Tell a story"
|

4. TensorRT-LLM原理
与其他部分推理引擎(例如vLLM)不一样的是:TensorRT-LLM并不是使用原始的weights进行模型推理。而是先对模型进行编译,并优化内核,实现在英伟达GPU上的高效运行。运行编译后模型的性能比直接运行原始模型的性能要高得多,这也是为什么TensorRT-LLM速度快的原因之一。
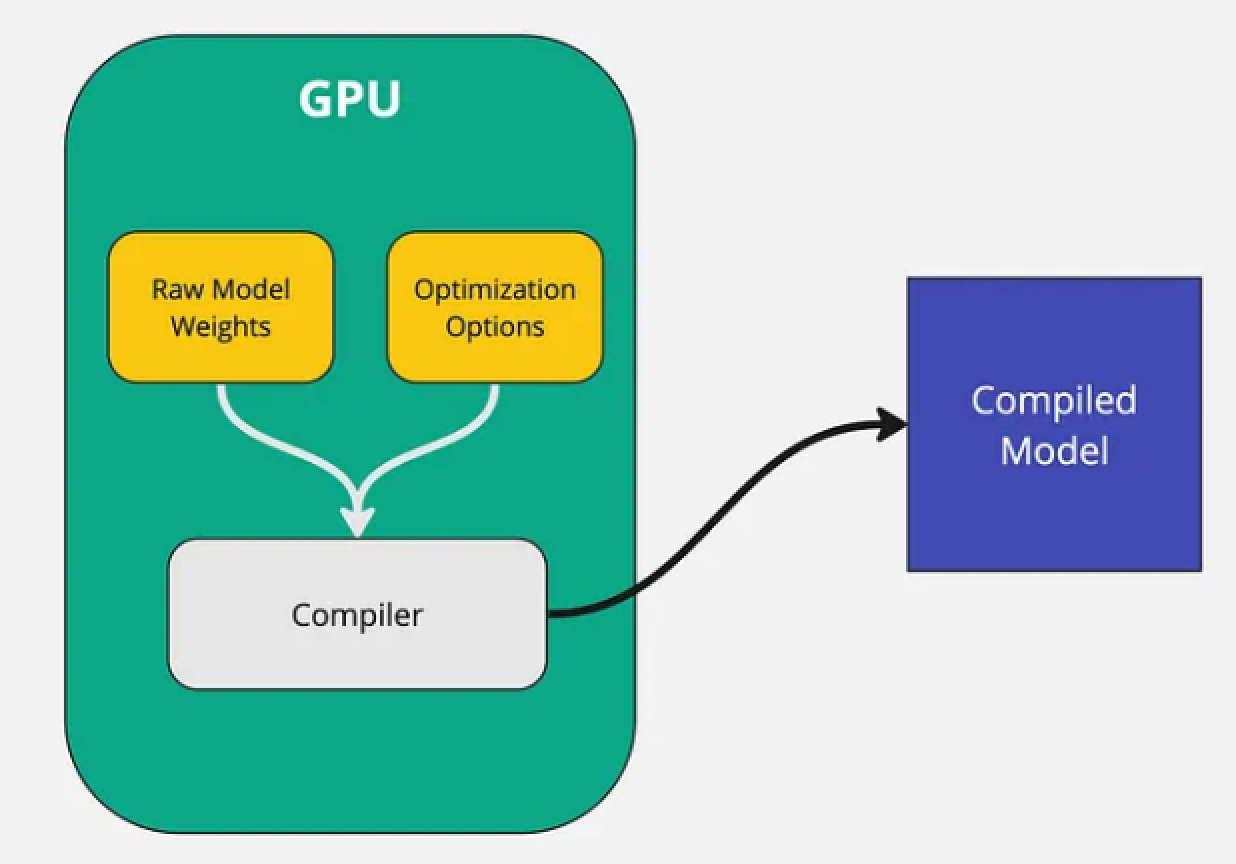
图片一:原始模型被编译成优化过的二进制文件[3]
原始模型的权重,与设定的优化选项(例如量化级别、tensor并行度、pipeline并行度等),一起传递给编译器。然后编译器根据这些信息输出特定针对GPU优化过的模型二进制文件。
需要注意的一个点是:整个模型编译的过程必须在GPU上进行。生成的编译模型是专门针对运行它的GPU进行优化的。例如,如果是在A40 GPU上编译的模型,就无法在A100上运行。所以在推理时,必须使用和编译时的GPU同一个类型。
TensorRT-LLM并不直接支持所有的LLM,因为每个模型的架构都不一样,TensorRT会做深层图级别优化,所以这就需要对不同模型进行适配。不过目前大部分模型例如Mistral、Llama、chatGLM、Baichuan、Qwen等都是支持的[4]。
TensorRT-LLM的python包使得开发者可以在不需要了解C++或CUDA的情况下以最高效的方式运行LLM。除此之外,它还提供了例如token streaming、paged attention以及KV cache等使用功能,下面我们具体进行介绍。
4.1. Paged Attention
Paged Attention无论是在TensorRT-LLM还是vLLM中,都是一个核心的加速功能。通过Paged Attention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高14-24倍的吞吐量[5]。
4.1.1. LLM的内存管理限制性能
在自回归解码过程中,LLM的所有输入token都会生成attention机制的keys和values的张量,并且这些张量被保留在GPU内存中,用来生成下一个token。大语言模型需要大量内存来存储每个token的keys和values,并且随着输入序列变长时,所需的内存也会扩展到非常大的规模。
这些缓存的key和value的张量通常称为KV缓存。KV缓存有2个特点:
- 内存占用大:在LLaMA-13B中,单个序列的KV缓存占用高达1.7GB的内存
- 动态化:其大小取决于序列的长度,而序列长度高度易变,且不可预测
在常规的attention机制中,keys和values的值必须连续存储。因此,即使我们能在给序列分配的内存的中间部分做了内存释放,也无法使用这部分空间供给其他序列,这会导致内存碎片和浪费。因此,有效管理KV缓存是一个重大挑战。
4.1.2. Paged Attention机制
为了解决上述的内存管理问题,Paged Attention的解决办法非常直接:它允许在非连续的内存空间中存储连续的keys和values。
具体来说,Paged Attention将每个序列的KV缓存分为若干个block,每个block包含固定数量token的key和value张量。在注意力计算过程中,Paged Attention内核能够高效地识别和提取这些block。由于这些block在内存中不需要连续,因此也就可以像操作系统的虚拟内存一样,以更灵活的方式管理key和value张量——将block看作page,token看作bytes,序列看作process。
序列的连续逻辑块通过块表映射到非连续的物理块。随着生成新的token,物理块会按需进行分配。这种方式可以防止内存碎片化,提高内存利用率。在生成输出序列时,page即可根据需要动态分配和释放。因此,如果我们中间释放了一些page,那这些空间就可以被重新用于存储其他序列的KV。
通过这种机制,可以使得极大减少模型在执行复杂采样算法(例如parallel sampling和beam search)的内存开销,提升推理吞吐性能。
4.2. KV Cache
KV Cache是LLM推理优化里的一个常用技术,可以在不影响计算精度的情况下,通过空间换时间的办法,提高推理性能。KV Cache发生在多个token生成的步骤中,并且只发生在Decoder-only模型中(例如GPT。BERT这样的encoder模型不是生成式模型,而是判别性模型)。
我们知道在生成式模型中,是基于现有的序列生成下一个token。我们给一个输入文本,模型会输出一个回答(长度为 N),其实该过程中执行了 N 次推理过程。模型一次推理只输出一个token,输出的 token 会与输入序列拼接在一起,然后作为下一次推理的输入,这样不断反复直到遇到终止符。
而由于每个token都需要计算其Key和Value(Attention机制),所会存在一个问题:每次生成新的token时,都需要计算之前token的KV,存在大量冗余计算。而在整个计算过程中,每个token的K、V计算方式是一样,所以可以把每个token(也就是生成过程中每个token推理时)的K、V放入内存进行缓存。这样在进行下一次token预测时,就可以不需要对之前的token KV再进行一次计算,从而实现推理加速。这便是KV Cache的基本原理,如果各位希望了解更多的细节,可以继续阅读这篇文章[6]。
5. TensorRT-LLM与vLLM对比
vLLM也是开源社区一个非常热门的推理引擎,上面提到的Page Attention这一重要就是源自vLLM。在使用两个引擎的部署过程中,笔者对两者有如下感受:
- vLLM非常易于使用:vLLM无论是环境准备(pip即可)、模型部署(不需要编译模型)还是上手难度(文档全面、社区活跃),均优于TensorRT-LLM。TensorRT-LLM的学习成本以及故障排查的难度都要高于vLLM
- vLLM支持的硬件部署选项更多:TensorRT-LLM作为英伟达推出的框架,主要是针对自家的GPU进行的优化,所以仅适用于Nvidia CUDA。而vLLM目前除了支持Nvidia CUDA,外,还支持AMD ROCm, AWS Neuron和CPU的部署
- 在性能表现上,参考社区在2024年6月使用LLAMA3-8B做的benchmark[7]测试,可以看到vLLM在TTFT(Time to First Token,即从发送请求到生成第一个token的时间,在交互式聊天场景较为重要)上表现不俗,优于TensorRT-LLM。但是在Token生成速率上TensorRT-LLM表现更好(特别是在做了4-bit量化后,两者表现差异更大)
总的来说,如果是团队有一定的技术能力、仅使用英伟达GPU,以及使用量化后的模型做推理的场景,可以优先考虑TensorRT-LLM,可以获得更高效的推理性能。
6. Nvidia Triton Inference Server
在TensorRT-LLM里我们可以看到它实现了模型的加载以及推理的调用。但是在生产上,我们不可能仅有这套API工具就足够,而还需要对应一套Serving服务,也就是一套Server框架,帮助我们部署各种模型,并以API的方式(例如HTTP/REST等)提供模型的推理服务。同时,还要能提供各种监控指标(例如GPU利用率、服务器吞吐、延迟等),可以帮助用户了解负载情况,并为后续扩缩容的推理服务的实现提供指标基础。
所以,要创建一个生产可用的LLM部署,可使用例如 Triton Inference Server的Serving服务,结合TensorRT-LLM的推理引擎,利用TensorRT-LLM C++ runtime实现快速推理执行。同时它还提供了in-flight batching 和paged KV caching等推理优化。
这里还需要再强调的是:Triton Inference Server,如其名字所示,它只是一个Server服务,本身不带模型推理功能,而是提供的Serving的服务。模型推理功能的实现,在Triton里是通过一个backend的抽象来实现的。TensorRT-LLM就是其中一种backend,可以对接到Triton Inference Server里,提供最终的模型推理功能。所以,Triton不仅仅是只能和TensorRT-LLM集成使用,还可以和其他推理引擎集成,例如vLLM。
在对Triton Inference Server有了简单了解后,下面我们介绍如何实现部署。
6.1. 部署推理服务
创建docker容器来部署推理服务
|
# 准备triton docker docker run -it --gpus all --network host --shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864 -v /home/ubuntu/data:/data nvcr.io/nvidia/tritonserver:24.05-trtllm-python-py3
# 下载tensorrtllm_backend git clone https://github.com/triton-inference-server/tensorrtllm_backend.git --branch v0.9.0 cd tensorrtllm_backend apt-get update && apt-get install git-lfs -y --no-install-recommends git lfs install git submodule update --init --recursive
# 将上面编译过的模型拷贝到其指定目录 cd tensorrtllm_backend/ cp /data/TensorRT-LLM/examples/llama/trt_engines/llama2-f16/* all_models/inflight_batcher_llm/tensorrt_llm/1/
# 配置config.pbtxt,指定例如模型的位置、使用的tokenizer、启用in-flight batching等 python3 tools/fill_tEMPlate.py -i all_models/inflight_batcher_llm/postprocessing/config.pbtxt tokenizer_dir:meta-llama/Llama-2-7b-chat-hf,tokenizer_type:auto,triton_max_batch_size:64,postprocessing_instance_count:1 python3 tools/fill_template.py -i all_models/inflight_batcher_llm/preprocessing/config.pbtxt tokenizer_dir:meta-llama/Llama-2-7b-chat-hf,tokenizer_type:auto,triton_max_batch_size:64,preprocessing_instance_count:1 python3 tools/fill_template.py -i all_models/inflight_batcher_llm/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:64,decoupled_mode:false,bls_instance_count:1 python3 tools/fill_template.py -i all_models/inflight_batcher_llm/ensemble/config.pbtxt triton_max_batch_size:64 python3 tools/fill_template.py -i all_models/inflight_batcher_llm/tensorrt_llm/config.pbtxt triton_max_batch_size:64,decoupled_mode:true,engine_dir:all_models/inflight_batcher_llm/tensorrt_llm/1,max_queue_delay_microseconds:10000,batching_strategy:inflight_fused_batching
# 启动serving服务,这里world_size表示使用多少个GPU用作serving huggingface-cli login --token xxxx chmod +r ./all_models/inflight_batcher_llm/tensorrt_llm/config.pbtxt python3 scripts/launch_triton_server.py --world_size 1 --model_repo=./all_models/inflight_batcher_llm/ |
而后即可正常启动Triton Server推理服务:
6.2. 使用推理服务
在Triton Inference Server启动后,即可使用HTTP的方式进行模型推理,例如:
|
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "What is ML?", "max_tokens": 50, "bad_words": "", "stop_words": "", "pad_id": 2, "end_id": 2}' {"context_logits":0.0,"cum_log_probs":0.0,"generation_logits":0.0,"model_name":"ensemble","model_version":"1","output_log_probs":[0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0],"sequence_end":false,"sequence_id":0,"sequence_start":false,"text_output":"What is ML?\n\nMachine learning (ML) is a subfield of artificial intelligence (AI) that involves the use of algorithms and statistical models to enable machines to learn from data, make decisions, and improve their performance on a specific task over time.\n"} |
6.3. In-flight Batching
在部署过程中,大家可能有注意到:在指定tensorrt_llm的backend时,我们指定了一个batching_strategy:inflight_fused_batching的配置项。这里In-flight Batching也是模型推理场景里的一个优化项,一般也称为Continuous Batching。
首先,Batching(批处理)的基本原理是:将多个独立的推理请求组合为一个批次,然后一次性提交给模型进行推理,从而提高计算资源的利用率。在GPU上的推理请求可以以4种方式进行Batching:
- No Batching:每次处理1个请求
- Static Batching:请求放入batch队列,在队列满时一次性执行这个批次
- Dynamic Batching:收到请求后放入batch队列,在队列满时或达到一定时间阈值,一次性执行这个批次
- In-flight Batching/Continuous Batching:请求按照token逐个处理,如果有请求已经完成并释放了其占据的GPU资源,则新的请求可以直接进行处理,不需要等待整个批次完成
为什么需要In-flight Batching?我们可以想象一个例子,在Static Batching的场景下,会有多个请求提交给模型去处理。假设一个批次有2个请求,其中request_a的推理需要生成3个token(假设耗时3s),request_b的推理要生成100个token(假设耗时100s),所以当前这个批次需要耗时100s才能结束。同时又来了request_c的推理请求,此时request_c智能等待。这样会造成2个问题:
- request_a只耗时3s即结束,但是由于它与request_b是同一个批次,所以无法在完成后立即返回结果给客户端,而是需要等待request_b也完成之后才能一起返回结果
- 新的请求request_c也必须等待前一个批次完成后(例如当前这个批次耗时100s),才能被模型进行推理
在这种方式下,可以看到,会有GPU资源空闲,得不到完全利用。并且会导致整体推理延迟上升。
而In-flight Batching的方式是:它可以动态修改构成当前批次的请求,即使是这个批次正在运行当中。还是以上面的场景举例,假设当前过去了3s,request_a已经完成,request_b仍需97s完成。这时候request_a由于已经完成,所以可以直接返回结果给客户端并结束。而由于request_a释放了其占据的资源,request_c的推理请求可以立即被处理。这种方式就提升了整个系统的GPU使用率,并降低了整体推理延迟。对应过程如下图所示:
图片二:Iteration Batching[8]
总结
从TensorRT-LLM+Triton这套方法的部署过程来看,还是较为复杂的,需要先对模型进行编译,还要特别注意环境、参数的设置,稍不注意就无法正常部署。除此之外,英伟达的文档也不够清晰。总体来说,学习成本比较高,但也带来了相对应的推理效果提升的收益(相对于vLLM在量化模型推理、以及token生成速度的场景)。但是,在模型推理场景下,推理效果也并不是唯一选择因素,其他例如框架易用性、不同底层硬件的支持,也需要根据实际情况进行考量,选择最合适推理引擎。
References
[1] TensorRT-LLM Installing on Linux: https://nvidia.github.io/TensorRT-LLM/installation/linux.html
[2] Llama2-7b-chat: https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
[3] Deploying LLMs Into Production Using TensorRT LLM: https://towardsdatascience.com/deploying-llms-into-production-using-tensorrt-llm-ed36e620dac4
[4] TensorRT-LLM 支持的模型: https://github.com/NVIDIA/TensorRT-LLM/tree/main/tensorrt_llm
[5] 比HuggingFace快24倍!伯克利LLM推理系统开源碾压SOTA,GPU砍半: https://baijiahao.baidu.com/s?id=1769290162439240324&wfr=spider&for=pc
[6] 大模型推理优化技术-KV Cache: https://zhuanlan.zhihu.com/p/700197845
[7] BenchMarking LLM Inference Backends: vLLM, LMDeploy, MLC-LLM, TensorRT-LLM, and TGI https://bentoml.com/blog/benchmarking-llm-inference-backends
[8] Iteration batching (a.k.a. continuous batching) to increase LLM inference serving throughput: https://friendli.ai/blog/llm-iteration-batching/











