介绍
我们很高兴分享“万事通”(Jack of All Trades,简称 JAT) 项目,该项目旨在朝着通用智能体的方向发展。该项目最初是作为对 Gato (Reed 等,2022 年) 工作的公开复现启动的,Gato 提出训练一种能够执行视觉与语言以及决策任务的 Transformer。于是我们首先构建了 Gato 数据集的开放版本。随后,我们在此基础上训练了多模态 Transformer 模型,并针对处理顺序数据和连续值引入了若干改进。
总体而言,该项目取得了以下成果:
- 发布了大量在各种任务上表现优异的 专家 RL 智能体 。
- 发布了 JAT 数据集 ,这是第一个用于通用智能体训练的数据集。它包含了由专家智能体收集的数十万条专家轨迹。
- 发布了 JAT 模型 ,这是一种基于 Transformer 的智能体,能够玩电子游戏、控制机器人执行各种任务、理解并在简单的导航环境中执行命令等!

数据集和专家策略
专家策略
传统的强化学习 (RL) 涉及在单一环境中训练策略。利用这些专家策略是构建多功能智能体的有效方法。我们选择了各种性质和难度不同的环境,包括 Atari、BabyAI、Meta-World 和 MuJoCo。在每个环境中,我们训练一个智能体,直到它达到最先进的性能水平。(对于 BabyAI,我们使用的是 BabyAI bot )。这些训练结果被称为专家智能体,并已在? Hub 上发布。您可以在 JAT 数据集卡 中找到所有智能体的列表。
JAT 数据集
我们发布了 JAT 数据集 ,这是第一个用于通用智能体训练的数据集。JAT 数据集包含由上述专家智能体收集的数十万条专家轨迹。要使用此数据集,只需像从? Hub 加载任何其他数据集一样加载它:
>>> from datasets import load_dataset
>>> dataset = load_dataset("jat-project/jat-dataset", "metaworld-assembly")
>>> first_episode = dataset["train"][0]
>>> first_episode.keys()
dict_keys(['continuous_observations', 'continuous_actions', 'rewards'])
>>> len(first_episode["rewards"])
500
>>> first_episode["continuous_actions"][0]
[6.459120273590088, 2.2422609329223633, -5.914587020874023, -19.799840927124023]
除了强化学习 (RL) 数据,我们还包含了文本数据集,以为用户提供独特的界面。因此,您还会发现 Wikipedia 、 Oscar 、 OK-VQA 和 Conceptual-Captions 的子集。
JAT 智能体架构
JAT 的架构基于 Transformer,使用了 EleutherAI 的 GPT-Neo 实现 。JAT 的特别之处在于其嵌入机制,该机制专门用于内在地处理顺序决策任务。我们将观测嵌入与动作嵌入交错排列,并结合相应的奖励。
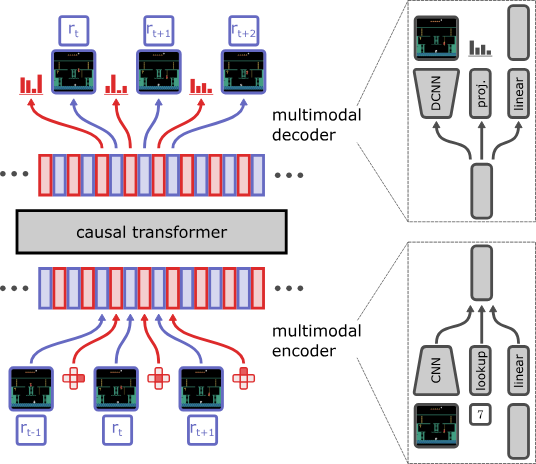
每个嵌入因此对应于一个观测 (与奖励相关联) 或一个动作。那么 JAT 是如何编码这些信息的呢?这取决于数据的类型。如果数据 (观测或动作) 是图像 (如在 Atari 中的情况),那么 JAT 使用 CNN。如果是连续向量,则 JAT 使用线性层。最后,如果是离散值,JAT 使用线性投影层。同样的原理也用于模型输出,具体取决于要预测的数据类型。预测是因果的,将观测值移位一个时间步长。通过这种方式,智能体必须根据所有先前的观测和动作来预测下一个动作。
此外,我们认为让我们的智能体执行 NLP 和 CV 任务会很有趣。为此,我们还让编码器可以选择将文本和图像数据作为输入。对于文本数据,我们使用 GPT-2 的标记化策略,对于图像,我们使用 ViT 类型的编码器。
考虑到数据的模态可能因环境而异,JAT 如何计算损失呢?它分别计算每种模态的损失。对于图像和连续值,它使用 MSE 损失。对于离散值,它使用交叉熵损失。最终损失是序列中每个元素损失的平均值。 等等,这是否意味着我们对预测动作和观测赋予了相等的权重?实际上并不是这样,但我们将在 下文 中详细讨论。
实验与结果
我们在所有 157 个训练任务上评估 JAT。我们收集了 10 个回合的数据并记录总奖励。为了便于阅读,我们按领域汇总结果。
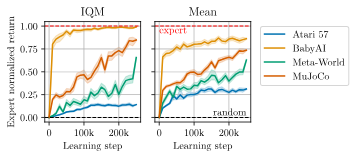
如果要用一个数字来总结这些结果,那就是 65.8%,这是在 4 个领域中相对于 JAT 专家的平均表现。这表明 JAT 能够在各种任务中模仿专家的表现。让我们更详细地看看:
- 对于 Atari 57,智能体达到了专家得分的 14.1%,相当于人类表现的 37.6%。在 21 个游戏中超过了人类表现。
- 对于 BabyAI,智能体达到了专家得分的 99.0%,仅在 1 个任务上未能超过专家得分的 50%。
- 对于 Meta-World,智能体达到了专家得分的 65.5%。
- 对于 MuJoCo,智能体达到了专家得分的 84.8%。
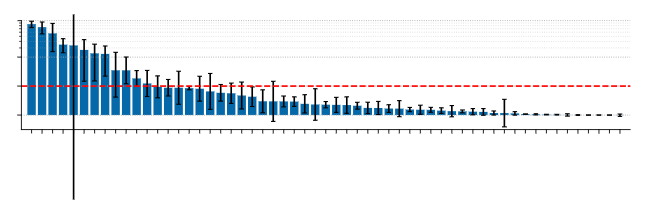
最令人印象深刻的是,JAT 在所有领域中使用 单一网络 实现了这一性能。为了衡量这一性能,让我们来看看 JAT 在一些任务中的渲染效果:

想试试吗?你可以的! JAT 模型 已在 ? Hub 上提供!
我们的模型显示了初步的文本任务处理能力,详情请参阅 论文 。
预测观测值的惊人好处
在训练 RL 智能体时,主要目标是最大化未来奖励。但是,如果我们还要求智能体预测它将来会观测到的内容,这个额外的任务会帮助还是妨碍学习过程呢?
对于这个问题有两种对立的观点。一方面,学习预测观测值可以提供对环境更深入的理解,从而导致更好更快的学习。另一方面,这可能会使智能体偏离其主要目标,导致在观测和动作预测方面的表现平平。
为了解决这一争论,我们进行了一个实验,使用了一个结合观测损失和动作损失的损失函数,并用一个加权参数 ( \kappa ) 来平衡这两个目标。
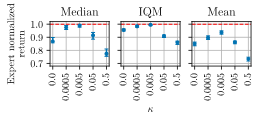
结果非常显著。当 \( k \) 值过高 (0.5) 时,预测观测的额外目标似乎阻碍了学习过程。但是,当 \( k \) 值较低时,对学习的影响可以忽略不计,智能体的表现与不将预测观测作为目标时相似。
然而,我们发现 \( k = 0.005 \) 左右是一个最佳点,此时学习预测观测实际上提高了智能体的学习效率。 我们的研究表明,只要平衡得当,将预测观测添加到学习过程中是有益的。这一发现对这类智能体的设计有重要意义,强调了辅助目标在提高学习效率方面的潜在价值。
所以,下次训练 RL 智能体时,可以考虑让它预测将来会观测到的内容。这可能会带来更好的表现和更快的学习速度!
结论
在这项工作中,我们介绍了 JAT,一个能够掌握各种顺序决策任务并在 NLP 和 CV 任务中表现出初步能力的多用途 Transformer 智能体。对于所有这些任务,JAT 都使用单一网络。我们的贡献包括发布专家级 RL 智能体、JAT 数据集和 JAT 模型。我们希望这项工作能够激发未来在通用智能体领域的研究,并有助于开发更多功能和更强大的 AI 系统。
下一步是什么?研究请求
我们相信,JAT 项目为通用智能体领域的研究开辟了新的方向,而我们只是刚刚开始。以下是一些未来工作的想法:
- 改进数据 : 尽管具有开创性,JAT 数据集仍处于初期阶段。专家轨迹仅来自每个环境中的一个专家智能体,这可能会导致一些偏差。尽管我们尽力达到了最先进的性能,但有些环境仍然具有挑战性。我们相信,收集更多的数据和训练更多的专家智能体将会 大有帮助 。
- 使用离线 RL : JAT 智能体是使用基本的行为克隆训练的。这意味着两件事: (1) 我们无法利用次优轨迹,(2) JAT 智能体不能超过专家的表现。我们选择这种方法是为了简单,但我们相信使用离线 RL 可以 大大提高 智能体的性能,同时实现起来也不会太复杂。
- 释放更聪明的多任务采样策略的全部潜力 : 目前,JAT 智能体从所有任务中均匀采样数据,但这种方法可能会限制其表现。通过动态调整采样率以集中于最具挑战性的任务,我们可以加速智能体的学习过程并释放 显著的性能提升 。
相关链接
- ? 论文
- ? 源码
- ?️ JAT 数据集
- ? JAT 模型
引文
@article{gallouedec2024jack,
title = {{Jack of All Trades, Master of Some, a Multi-Purpose Transformer Agent}},
author = {Gallouédec, Quentin and Beeching, Edward and Romac, Clément and Dellandréa, Emmanuel},
journal = {arXiv preprint arXiv:2402.09844},
year = {2024},
url = {https://arxiv.org/abs/2402.09844}
}
英文原文: https://hf.co/blog/jat
原文作者: Quentin Gallouédec, Edward Beeching, Clément ROMAC, Thomas Wolf
译者: xiaodouzi











